
Updated December 9, 2010
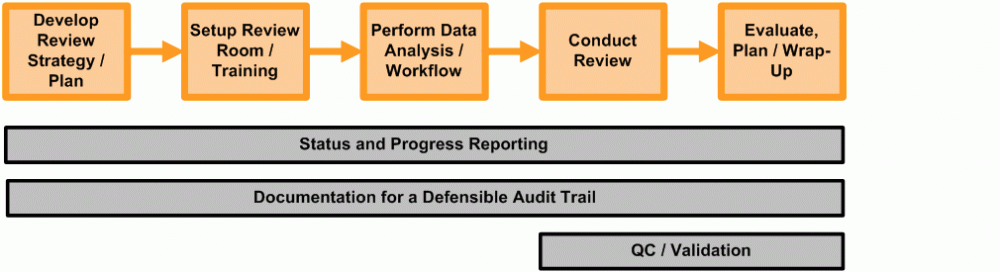
1.1. Overview
Historically, lawyers were obligated to review every document presented to them by the client or opposing counsel in the litigation for relevance, responsiveness to discovery requests, and privilege. With the explosion of email and other electronic documents, reviewing each and every document is often unrealistic. A key strategy is to control the scope of the review through the use of technology or other aids and should be discussed and agreed upon during the initial planning meetings.
Techniques that can be useful to limit the scope include:
- Strategic collection of data – it may be possible to do a more selective collection of key custodian data rather than a broad collection. There may be agreed upon file types or directory locations or key personnel.
- Strategic filtering of collected data – this may take the form of applying date limitations and/or keyword filters against the data that has been collected.
- Keeping ESI in its native format rather than a rendering to TIF or other image format.
In addition to limiting the scope, determine if the scope of the review is going to be “all ESI” or a hybrid of ESI and paper.
Once the scope is known, the selection of a knowledgeable review manager for the process is an essential. The review manager must assure that those selected to conduct the review have a clear understanding of the case objectives. Additionally, it can be helpful to determine who else will comprise the review team and create an organization chart to ensure that all parties to the review know their role: corporate counsel, outside counsel, and, if needed, external reviewers.
The review manager should create clear documentation of the key issues and a distinction between issues of fact and issues of law. This documentation is generally captured in the form of Review Guidelines. These guidelines should not only identify the scope of the review and what the team will be looking for, but also include exemplar documents of the kind of evidence the litigation team will need to effectively prosecute or defend the matter. An understanding of who the key players are and what roles each plays in the case will enhance the review team’s ability to hone in on the critical pieces of evidence. Many times it helps to create an organization chart of the key players to further identify their relationships to one another and to the matter.
The review objectives may evolve as a case progresses through the litigation. As it does, it is the responsibility of the review manager to update the review guidelines so that they remain current with the ongoing review. The following represents a few types of review that may be undertaken:
- Determine the relevancy of the information or documents collected or produced
- Use database fields, marks or tags within the application to categorize documents
- Determine whether or not any privilege applies to the documents subject to production
- Determine to which request(s) for production the documents are responsive
- Identify documents that should be marked as “confidential” or have portions redacted
- Relate key documents to alleged facts or legal issues previously outlined in the case
- Relate key documents to key players who may testify about the documents
In some circumstances, a single review may encompass all these objectives. In others they are done in phases and by a variety of different reviewers.
All members of the review team should have summaries of any discovery requests and answers thereto. Any special discovery orders or stipulations should also be summarized for the review team to make sure that the review is conducted in compliance with those orders or agreements. The review team should receive training on the matter itself, and the review application selected.
Agreements made during the meet-and-confer process will influence the review objectives, techniques used, platform chosen and the overall project workflow and milestones. Discovery deadlines will also influence the review strategy. For instance, a DOJ second request with a 15-day turnaround might be handled differently than a standard litigation matter with a more long-term discovery schedule.
1.2. Meet and Confer
The case team must make a determination about the scope of the review: what is to be reviewed, how it is to be reviewed, and what is the intended outcome. The discovery order will direct what data is to be collected and reviewed. A meet-and-confer conference between the parties should be conducted early to make these decisions. The Federal Rules of Civil Procedure 26(f) states that these initial meetings are to include discussions on matters pertaining to ESI. ESI topics include preservation, the form of production, and privilege and work-product protection claims.
1.3. Rules of Engagement (Protocols and Workflow)
Review Guidelines are typically prepared to define not only the objectives of the review but the rules of engagement for the review team. Historically, a coding manual defined the bibliographic fields that were to be captured by the reviewers into the review database. Today, with many reviews being done in digitized databases that already capture much of this information, the review guidelines are really designed to address how to categorize documents for their use in the course of the matter.
Examples of information that may be captured in the review guidelines include:
- Rules for adding information to the database such as: type of document, entities named in the document, marginalia found on paper docs that have been scanned, etc.
- Publication of look-up table to aid in identification of key players and known entities
- Rules for identification and categorization of the responsive and producible documents with an outline of the issues and possibly sample documents
- Rules for the handling of documents requiring redaction
- Rules for identifying and categorizing privilege documents and handling confidentiality issues
- Rules for adding annotations to documents in the form of attorney notes and workproduct
- Rules for categorizing emails and their attachments and email threads
- Rules for the identification and tagging of non-responsive documents, spam and junk email
- Rules for handling of unreadable, password protected or other faulty documents
Methodologies and workflow can be impacted by multiple factors:
- Agreements made by counsel during the meet and confer phase or as ordered by the court
- Time and cost constraints for the project
- Collection and restoration methods
- Format of the documents (ESI or paper or combination)
- Functionality available within the review platform
- Available resources to support different formats
1.4. Physical Format
Determining the physical format for the review should be established during the initial planning stages. A review may take many forms and utilize several different formats: Manual paper review, ESI or paper review using an in-house review system, using a hosted online system, using temp attorneys, or using an external service provider (domestic, offshore, or hybrid).
1.5. Review Assignments
In a typical scenario, the documents to be reviewed are divided up such that each reviewer is reviewing a specific numbered range of records that do not overlap with any other reviewers.
The review sets may be divided based on the source of the records or a subset of records for a particular key player, date range or case issue. The review assignments are then based on the importance of the source or key player, for example, with higher level attorneys reviewing the most critical key players’ records, and more junior level or paralegals reviewing less important ones.
To aid in an expedited privilege review, searches may be conducted for names of attorneys or law firms that would indicate a high probability of the result set containing attorney/client privileged communications. Documents meeting the privileged search criteria could be assigned to an attorney whose task is to review for privilege and mark the documents as such.
1.6. Project Management
The design of a project timetable or workflow is critical to the review process and should be established at the outset of the project. The workflow should be designed by the review manager with the assistance of any outsourced service provider retained and the organization’s internal litigation support personnel. Often, those most familiar with the technology will be able to provide invaluable guidance on how to leverage that technology to maximum advantage.
Other factors to consider regarding the creation of a project timetable include:
- Overall volume of data to be reviewed and complexity of the issues being reviewed
- Discovery deadlines
- Internal resources devoted to the review project
- Volume of redactions and the workflow provided to perform them
- Resource availability of all stakeholders: corporation, outside counsel, and service provider
- Ability of the service provider to produce to requirements; a sample run should be performed well in advance of any deadlines
The timetable should include:
- Deliverable deadlines for each phase of the project:
- Collection and restoration of the data
- Processing, searching, and hosting the data
- Review of the data (first pass, second pass, privilege reviews)
- Production of responsive documents
- Daily, weekly, monthly document totals per reviewer
- Other metrics to be used to measure the progress of the review and their milestones
- Production due dates set forth by the document request or the court
Milestones may be tied to specific custodians who are important to the matter, or critical time periods, issues or concepts. Using the power of the review tool to manage the workflow by segregating documents along these lines can greatly increase the project’s speed and efficiency.
Another key to ensuring that the workflow proceeds smoothly is to determine who will create the work assignments and how and when they will be disseminated to the review team members. Depending on how a project is staffed, work assignments may be created by the outsourced service provider, the review manager, a paralegal or someone in the organization’s litigation support department.
1.7. Vendor Selection
In evaluating these solutions it is recommended that the following questions are asked to vendors:
- Can the solution return search results fast enough at the desired scale so that it is easy to iteratively refine search queries?
- Does the system rank the search results by relevance and what criteria does it use?
- How do conceptual search systems determine the “concepts”? Does the user participate in the creation of a thesaurus or are the concepts automatically identified by the technology?
- Does the auto-categorization tool perform a first cut categorization automatically or require reviewers to submit criterion?
- Does the system allow the review team to further tailor the categories to its review?
- How does the solution allow reviewers to filter their keyword search results?
- What algorithms are used to identify email threads, duplicates or near-duplicates?
- How does the solution determine the various people involved, and how does it map variants such as multiple email aliases, multiple email addresses to the same initial?
1.8. Vendor Relationship
The review team should work with the electronic discovery outsourced service provider to develop the most efficient workflow for the project. Often, the outsourced service provider will be able to counsel the review team on the most efficient approach based on the strengths or limitations of the review tool. Do not assume that the workflow that worked in your last case using a different tool will work the same way on the next case and a different review platform. Work with the entire team to develop the methodology and workflow that makes the most sense given the needs of each specific case.
1.9. Joint Defense
If you are part of a joint defense group, you need to assure that the service provider you select can handle multiple parties and provide effective security to the data. Specifically, each law firm may want to ensure that their document tagging and notes are not visible by other parties.
1.10. Technologies
Modern-day electronic discovery is a time consuming and costly endeavor. Every additional hour of reviewer time that must be spent culling down large data sets to the ultimately responsive documents is additional cost. Utilizing technologies that reduce the number of documents requiring review or increase the speed of review can translate into significant cost savings. Technology can also be used to increase the quality of review by making it easier to discern key facts or relationships.
1.10.1. Metadata
Metadata is typically described as data about data. There are three sources of metadata. Most often we think of it as the operating system data that appears when you view a file list (title of document, date created, date modified, size, folder name, etc.) and the “Properties” of the document (original author, page count, template used to create, date printed, etc.). A document collection may have MS Word documents, MS Excel, Adobe PDF, MS Powerpoints, RTFs or plain text files, as well as emails, photographs, graphics, video and audio files. Each of these software applications contains metadata, but it may be stored inside the files in different locations depending on file type.
E-mail metadata contains even more information regarding the creation, forwarding information, delivery path and receipt of the email.
Metadata is also the data found in the body of the document such as comments inserted by the author, document deletions and/or revisions. This type of metadata is viewable in a native document with just a few mouse clicks. Depending on the review platform being used these forms of metadata may not be detected and made visible to the reviewer.
Depending on the nature of the case and the issues at hand, the metadata may be extremely important. Consider a situation where there is an allegation that an email has been altered or falsified. Analysis of the metadata for that email will verify where and when the message was sent, where and when it was received, and the size of the message.
A review platform should not only accommodate the display of this data for review, it must also allow for searching of the data in conjunction with, as well as separate from, the text of the actual document. The system should also allow sorting by these fields for ease of organization and review.
1.10.2. Keyword Search
Keyword searching was the first significant enhancement to the efficiency of the electronic document review process, reducing data sets that can be terabytes in volume to far more manageable sizes. Search effectiveness can be measured by recall, the number of responsive documents retrieved divided by the total number of responsive documents, and precision, the number of responsive documents retrieved divided by the total number of documents retrieved. Boolean, which allows for use of AND, and NOT operators in search queries, and proximity search, which finds documents that contain terms within a specified distance of each other, have been used to improve precision by reducing false positives. Stemming, wildcard and fuzzy search have been used to improve recall by finding variations of the search word that have the same or similar meaning. Search performance and scalability are also critical to search effectiveness. Search technology needs to be able to search millions of documents and return results in seconds in order to enable interactive and iterate searching and exploration of information.
1.10.3. Relevance Ranking
Relevance ranking is a way of scoring documents within a search result based on how well the document may match the search query. Two of the most common ways to measure relevance are term frequency and inverse document frequency. Term frequency measures the number of times the keyword exists in a document. Inverse document frequency measures the importance of a term within a set of documents or corpus by calculating the number of documents that contain the term out of the total number of documents. Documents are scored higher if they have a high term frequency but are scored lower if the term appears in a lot of documents within the corpus. Relevance ranking helps reviewers focus on the most important documents first, improving the quality and speed of the review.
1.10.4. Concept and Context Searching
“Concept” and “context” searching are technologies which offer users the ability to increase the efficiency and effectiveness of searching and review. Concept search technology may be based on neural networks, Bayesian methods, latent semantic indexing, or other high-level mathematical algorithms designed to learn the underlying associations among the words. Most methods rely on linguistic analysis to identify sentence structure, part of speech, and noun phrases, and allow the reviewer to search the documents for similar concepts without having to match an exact keyword or phrase. Concept-based tools may also use customized thesauri and semantic networks although these may require human intervention.
Context searching allows the user to define a search through keywords or phrases and then direct the system to find “similar” or “like” documents, which is particularly useful when a reviewer stumbles upon a key issue previously unidentified.
A concern with both technologies is the precision of the results. They are very useful in increasing the recall (number of results), but the precision (or relevancy) of the results may suffer.
1.10.5. Auto-Coding or Clustering
Auto-coding or clustering utilizes search technology to automatically identify ‘like’ documents and form them into groups for review purposes. The underlying technology that performs this sorting typically utilizes some type of linguistic analysis, thesauri or concept searching.
Two basic approaches to clustering like documents exist: rules-based and example-based. A rules-based approach often provides higher recall than keyword searching as the search engine may use proximity, word patterns, co-occurrence of key concepts and/or thesauri to determine search “hits”.
In an example-based approach, documents programmatically describe themselves based on the concepts that are identified within each document. The system then groups documents that are contextually similar together for review.
1.10.6. Filtering
Filtering refers to searching documents by meta-data, such as custodian, date-range, file type, sender, recipient, etc. Filtering can be useful for removing, or filtering documents that don’t match specified meta-data, and for identifying potentially relevant information. Automatically generated filters can also allow the user to quickly learn key facts about their documents, such as who are the most frequent senders or recipients of emails in this set of documents.
1.10.7. Near-Duplicate Detection and Review
Near-duplicates are documents that are not identical but only have small differences in content and/or metadata. A word processing document that has been edited by a team of people is a typical example of a near-duplicate file. This document may exist in multiple versions on different custodian hard drives and may also be attached to multiple emails. Software can detect near-duplicate documents.
1.10.8. Discussion Threading
Software that recreates discussion threads aids the review process by making it easier for reviewers to follow conversations, understand the context of emails, identify who said what when, and tag all emails in a thread at one time. There are two primary methods by which software can identify individual emails as being part of a thread: metadata-based and content-based. Metadata-based discussion threading relies on discussion identifiers that email applications will associate with individual emails or on grouping emails by their subject. Content-based threading can identify emails that are contained within other emails and using deep content analysis to identify which emails are parts of a thread. More and more complete threads can significantly increase the efficiency of review.
1.10.9. Social Node Connections
Software can also be used to map social connections, or email conversations. Quite often who knew what, when they knew it and who communicated it to them are key considerations of a case. Social network or people analysis technology allows the reviewer to determine who a custodian communicates with about certain topics, and trace a custodians email conversations.
1.11. Benefits of Technology Use
1.11.1. Review Less
The first way in which these technologies can benefit the review process is by reducing the number of documents that need to be individually reviewed. This can have a dramatic impact on the cost and time of review. It can also improve the quality of review by removing clearly irrelevant information allowing reviewers to focus on more relevant documents. The two principal ways of reducing the number of documents to be reviewed are to search for potentially relevant documents and only review those documents, or to cull out irrelevant documents. These two approaches are not mutually exclusive and can be used in conjunction with each other.
Keyword searches have been the most common way to find potentially relevant documents for review. Increasingly, practitioners are supplementing basic keyword searching with more sophisticated keyword search functionality such as wildcard, Boolean, proximity and concept search in order to both increase recall and precision.
These technologies can also be applied to culling out irrelevant documents, or grouping data that needs to be reviewed separately. For instance, automatically generated sender domain filters, or clustering can be used to identify junk or spam email that can culled in bulk from a matter. Similarly, a combination of keyword searching, filtering and social network analysis can be used to identify relevant custodians, irrelevant custodians and people engaging in potentially privileged communications. Duplicate and near-duplicate detection can also reduce the number of documents to be reviewed by removing duplicates and making it easy to perform batch analysis and coding saving reviewer time and costs. Searching for or grouping of foreign language documents can be used to set aside these documents for analysis by reviewers with foreign language expertise.
1.11.2. Review Faster
Review technology can also be applied to increase the number of document decisions made by reviewers within a given time period. Discussion threading technology speeds review by making it easier for a reviewer to understand the context of emails within a thread and to tag all the emails in a thread at one time. Near-duplicate detection saves time by allowing a user to review all non-culled near-duplicates once and bulk code them. Auto-coding or clustering can be used to group similar documents together allowing a reviewer to more quickly tag these documents. In some instances, auto-coding of documents is also being considered as a replacement for human review. Faster review is attractive because it can have a direct impact on the overall cost of review by reducing the number of hours expensed by reviewers, and because it can help when there are tight deadlines. Faster review also helps improve the quality of review by making it faster to learn key facts about the case.
1.11.3. Improved Review Quality
Review technologies can improve the quality of review. Relevance ranking allows reviewers to examine the most important documents first, which can be critical to rapidly understanding the nature of a case. Social connections and discussion threading can make it easier to identify key people, custodians, and documents. Concept search and clustering can help reviewers identify additional words or concepts that are relevant to a case. The ultimate benefit of all these technologies is that they enable reviewers to assess the nature of the case and develop a legal strategy faster and more thoroughly than before, improving decision-making and the eventual outcome of a case.