
Introduction
The term “search” is used interchangeably in records management, archiving, and e-discovery. One might assume all search is similar — not only from a technical perspective, but also from the perspective of intent. But they are not. Some searches have much more legal impact than others.
Within EDRM search is used broadly in many contexts: to assess or scope a matter, acquire specific documents or discrete information, or classify pre-selected documents, with minimal legal impact. For other EDRM searches, by contrast, the legal impact is high, such as in asserting comprehensiveness and accuracy.
Yet enterprise search, early data assessment, e-discovery processing search functions, review system search functions, and even concept analysis or document clustering tools are all described as “search” in the context of EDRM with little recognition of the fact that poor accuracy in one context is significantly more consequential than in others. This is why understanding the intent of a search is critical.
It is the intent of the search that should determine the appropriate technology, process, or workflow, that should be implemented, and the level of scrutiny to be applied in determining “reasonable” success. For this reason the EDRM Search Intent Model was created to define and document the different classes and subclasses of Search Intent that comprise the EDRM.
The Search Intent Framework is the result of considerable time and effort by members of the EDRM Search Team, led by Dominic Brown (HP Autonomy). Contributors include: Gene Eames (Pfizer), Chris Paskach, Phil Strauss, Mark Lindquist, Wade Peterson (Bowman and Brooke), Brent Larson (Bowman and Brooke).
Search Intent Classes
The EDRM Search Intent Framework describes three classes of search intent:
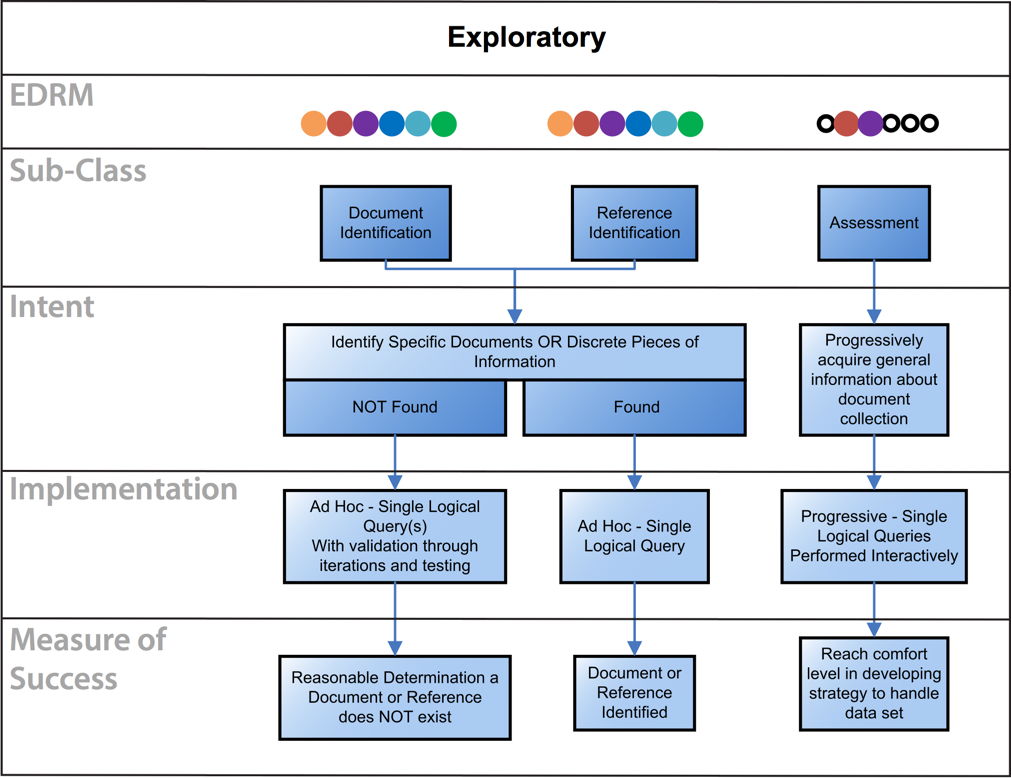
- Exploratory Class: The purpose of the Exploratory Class is to confirm whether or not a specific document, reference, or discrete piece of information exists. It also is used to gain general knowledge about a document set in order to understand how to handle the data set.
- Classification Class: The purpose of the Classification Class is to categorize individual documents or a set of documents as to their responsiveness, non-responsiveness, whether or not they flag a policy, and so forth.
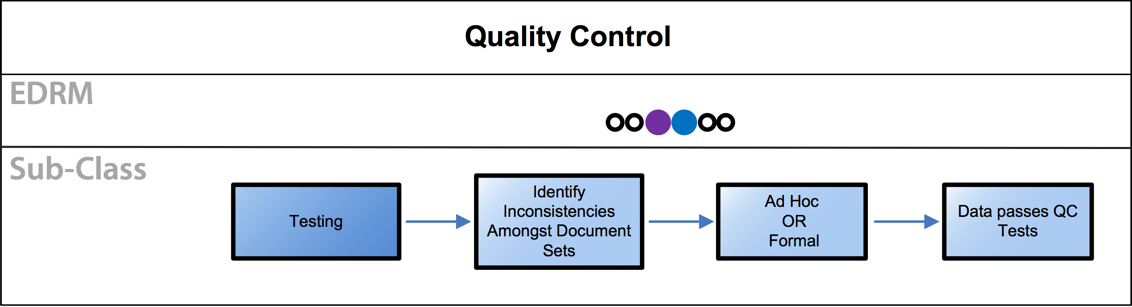
- Quality Control: The purpose of quality control testing is to identify inconsistencies in a document set. Quality control testing is typically done during review and production to test that documents are properly coded and are appropriate to either be produced or not produced.
Legend
| Information Governance | Identification | Preservation and Collection | Processing, Review, and Analysis | Production | Presentation |
Exploratory Class
| Sub-Class | Description |
|---|---|
| Document Identification | Determine whether a specific document exists. The typical approach is to run a set of queries to find the document. If the document is found, no validation is required. If the document is not found, further queries should be run to ensure the document was not inadvertently missed. If the document is still not found, test the comprehensiveness of your search methodology. It’s also appropriate to investigate the data processing and indexing endeavor—sources indexed, data processing exceptions, etc.—to be sure that all files and data sources were properly indexed and processed. |
| Reference Identification | Determine whether a specific reference, or discrete piece of information, exists. The typical approach is to run a set of queries in an effort to find the reference. If the reference is found, no validation is required. If the reference is not found, further queries should be run to ensure the reference was not inadvertently missed. If the reference is still not found, test the comprehensiveness of your search methodology. It’s also appropriate to investigate the data processing and indexing endeavor (sources indexed, data processing exceptions, etc.) to be sure that all the files and data sources were properly indexed. |
| Assessment | Acquire general information about a document collection. Typically a progression of single logical inquiries are run with the results analyzed until reaching a comfort level in developing a strategy to handle the data set. |
Classification Class

| Sub-Class | Description |
|---|---|
| Surveillance | Identify malfeasance via running iterative searches on electronic communications — email, IM, Social Media and so on. The most prevalent use case is banks complying with SEC, NASD, and FINRA regulations. Regulations require banks to supervise communications between registered broker dealers and their clients. Searches in this case are designed to identify insider trading, collusion, unlawful gifts, etc. Search terms and lexicons are tweaked to ensure that they are neither over inclusive or under inclusive. Use cases such as pharmaceutical companies trying to identify off label marketing or any organizations concerned about ongoing malfeasance are also common. |
| Review Set Exclusion | Identify a set of non-responsive documents to withhold from review. This process involves executing, tracking, reporting, and measuring the impact of sets of multiple logical queries. Iterative searches are run until reaching a comfort level that reasonable steps were taken to ensure the results are not over inclusive. |
| Review Set Inclusion | The purpose is to identify potentially responsive documents to include in a review set. This process involves executing, tracking, reporting, and measuring the impact of sets of multiple logical queries. Iterative searches are run until reaching a comfort level that reasonable steps were taken to ensure the results are not over inclusive. |
| Privilege | Identify a subset of potentially privileged documents, usually from the set of documents already selected for review. The typical approach is to run a series of logical queries based on assumptions of what will be privileged. These queries should be tracked and measured in order to evaluate their impact, and the process iterated until satisfied with its efficiency. The identification of privileged documents requires more stringent validation than many other classification queries. This is because case law suggests that the reasonableness of the attempts to avoid inadvertent disclosure of privileged information can play a role in the determination of waiver. This is especially true if portions of the review population will be produced without lawyer review. |
| Subject Matter | Identify subsets of documents by subject matter, usually from the set of documents already selected for review. The typical approach is to run a series of logical queries based on assumptions of what each subject will contain. These queries should be tracked and measured in order to evaluate their impact, and the process iterated until satisfied with its efficiency. Because the intent of subject matter classification is often solely for review efficiency, there is usually only a limited need for validation. However, the degree of scrutiny as to the accuracy of the process rises if review calls will be based solely upon search-dependent classification. |
Quality Control Class
| Sub-Class | Description |
|---|---|
| Testing | Identify inconsistencies in a document set. Quality control testing is typically done during review and production to test that documents are properly coded and are appropriate to either be produced or not produced. The testing can be formal or ad hoc depending on the circumstances. Concerns about ongoing malfeasance are also common. |