
Updated November 4, 2010
Aim: To prepare and produce ESI in an efficient and usable format in order to reduce cost, risk and errors and be in compliance with agreed production specifications and timelines.
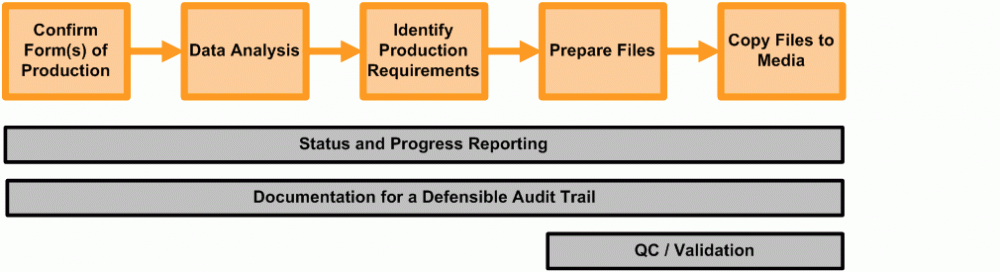
* Although represented as a linear workflow, moving from left to right, this process is often iterative. The feedback loops have been omitted from the diagram for graphic simplicity.
Introduction
With the unprecedented increase in the amount of electronically stored information (ESI) that is being created and stored in the corporate community, there has been a corresponding increase in focus on how the data that has been collected and reviewed is ultimately produced in civil litigation and regulatory investigations. Because of the complexity, the potential costs and the significant risks associated with producing ESI, the topic has been addressed in a growing number of articles, white papers and judicial opinions. As a measure of the significance of the topic, production of ESI is addressed directly in the Federal Rules of Civil Procedure which were amended effective December 1, 2006.[1. Federal Rules of Civil Procedure, Rules 16, 26, 33, 34, 37 and 45.] For example, Rule 26(f) sets an expectation that the method and format by which ESI is to be produced should be considered and negotiated by the parties early in the discovery process. The production of ESI continues to present challenges in the discovery process even though specific rules have been drafted, commented on, redrafted and approved to address the issues.
This section addresses the options and the variables for the production of ESI.
1. Confirm Forms of Production
1.1 Involvement of the Technical Team
In the pre-e-discovery world, discovery was handled almost entirely by the legal team. In the e-discovery era, the early involvement of technology and technicians is critical to ensure a smooth and efficient production. Technical team members might include the corporation’s IT personnel, a service provider’s and outside counsel’s project managers, the corporation’s and outside counsel’s litigation support analysts and more. Ideally, technical team members are consulted prior to the meet and confer regarding production. These technical team members can be invaluable in consulting regarding production forms prior to the meet and confer as well as establishing processes and analyzing data to ensure the efficient and complete production and receipt of documents. Consider providing members of the technical team a copy of the document requests and agreements between the parties about the method, form and content of the productions. This information will facilitate communications between the legal and technical teams regarding the contents and completeness of the production from a technical perspective. An example of this is a case in which the analysis of schematics and drawings is important. If the technical team members know to expect such documents and none or fewer than expected are produced, that issue can be addressed early in the production. It may be that those types of files are kept on a shared location of the corporation’s server that was overlooked in the collection of documents.
1.2. Federal Rules of Civil Procedure
Negotiations about the form in which the production of documents by all parties will be made should have already occurred by the time documents are being prepared to be produced. Rule 26(f) of the Federal Rules of Civil Procedure states that “parties must confer as soon as practicable – and in any event at least 21 days before a scheduling conference is to be held or a scheduling order is due under Rule 16(b)…” as to “any issues about disclosure or discovery of electronically stored information, including the form or forms in which it should be produced.” It is clear the intent is that parties will discuss and plan for the production of documents in the initial stages of the litigation. From a practical standpoint, the determination and agreement about the form(s) of production must be considered and made at the initial stages of the e-discovery process because some methods of collection and processing may preclude some forms of production.
Rule 34(b) provides that a requesting party may specify the form or forms of production. If the request fails to do so or if the responding party objects to the requested forms of production, the responding party must state its intended forms of production in its response to discovery requests.
A Committee Note to Rule 26(f)(3) states that “parties may be able to reach agreement on the forms of production, making discovery more efficient.” To reach such an agreement and to know in what form – or forms – to request production, it is important to fully understand the types of ESI available for production, the nature of that ESI and how those factors will impact the ability to discover the knowledge needed to address the issues in the matter. Consider the situation in which opposing counsel, after receiving a production of images, determines the spreadsheets in image format do not provide the information requires to completely analyze the documents. The issue is considered upon motion by the court and the court rules that production of spreadsheets must be in native format. The producing party must now re-review and re-produce the spreadsheets in native format, resulting in increased cost and wasted time. A “meet and confer” conference held between knowledgeable and informed representatives of all parties which thoroughly addresses all aspects of the production of ESI will result in a clear roadmap for collection, processing and production of documents.
1.3. Production Capabilities and Limitations
As previously discussed, at the very inception of the discovery process, consideration must be given to how the ESI will be processed and produced. Will a third party service provider, outside counsel’s litigation support department or the in-house litigation support department handle the technical work? It is important to understand the capabilities (and limitations) of the service provider or litigation support department that will be processing the electronic data but it is just as important to explore those issues as they relate to preparing the final document production. Be sure the chosen group can actually produce documents in the formats agreed upon during negotiations and that the production process can be done timely. Early discussions with the service provider or litigation support department who will be providing the technical services and support will ensure that the requirements for the form or forms of the production can be met. This will also reduce the likelihood of delays during the final stages of production resulting from undisclosed expectations or erroneous assumptions.
1.4. Communication Between Parties
Rule 26(f)(1) requires an initial conference between parties. During negotiations and throughout the discovery process, communication between representatives from each party with technical knowledge about the data of the party they represent will make the production process more efficient and, therefore, less costly in time and money. These representatives may be from the service provider, from the outside counsel’s litigation support department, a paralegal or an attorney from either the corporation or the outside counsel’s office, IT personnel from the corporation or other. The purpose of these communications is to share information about the sources and types of potentially relevant ESI, what is considered to be accessible and inaccessible, and the forms and formats for production of the different types of relevant ESI. Discussions should also include technical specifications for the format in which each requesting party will require data to be delivered. Ongoing communications will most likely be necessary to address unexpected issues as the production process proceeds. Because there are so many variables and options for producing ESI, it is not possible to accurately know what the requesting party will need or want without communicating about it ahead of time.
1.5. Rolling Production
A rolling production is a negotiated schedule for producing data in stages rather than all at once. This production option might be negotiated in circumstances in which there are large volumes of data to be reviewed and produced in a short timeframe. Some considerations include:
- A rolling production provides an opportunity to identify issues early in the production, allowing problems to be remedied before all the data has been processed and produced.
- If depositions are approaching or access to the data is needed immediately, review can begin without having to wait until the entire production is completed.
- Prioritize the order in which the data will be processed and produced on a rolling basis. Request that critical custodians’ data or those whose depositions are scheduled be processed first.
- Implement a process to manage the review of documents produced on a rolling basis to prevent the possibility that reviewers will review the same documents multiple times, or worse, miss some documents. See the Processing Guide for information regarding the deduplication process and its implications.
2. Data Analysis
One of the first steps in production is to analyze the records and determine production forms. To be sure the data necessary to allow thorough analysis of the discovery documents are produced, it is critical to understand how different types of documents are impacted by processing and production form(s) (see the Processing Guide). For example, formulas are not viewable when spreadsheets are converted to image; blind copyees and the date read are not available when emails are converted to image; and speaker notes may not be viewable when MS PowerPoint presentations are converted to image. The determination of whether or not that information is necessary should be made early in the discovery process. Considering in advance what options are available and determining the most useful production form(s) for each file type is essential for negotiating production options and ensuring the legal team receives what they need.
The forms of production are:
- Native – Files are produced in their native format. This production form may include load files, extracted metadata and searchable text.
- Near-Native – Files are extracted or converted into another searchable format that approximates the native format. This production may include load files, extracted metadata and searchable text.
- Image (Near-Paper) – Files are converted to image files, typically .tif or .pdf. This production may include load files, extracted metadata and searchable text.
- Paper – ESI is produced in paper format.
3. Identify Production Requirements
The record set may include word processing files, spreadsheets, email, databases, drawings, photographs, data from proprietary applications, website data, voice mail, and much more. To understand what data should be produced in light of the issues specific to the subject case, it is necessary to understand what information is available in the different software applications (or types of documents). Such preparation mitigates the risk of discovering too late that the agreed-upon production form is inadequate to provide the discovery needed to address and understand the issues in the dispute or investigation. In the past, with paper productions there was typically only one component to a document production – the paper documents. ESI productions often have more than one component.
FRCP 34(b)(1)(E)(ii) states “if a request does not specify a form for producing ESI, a party must produce it in a form or forms in which it is ordinarily maintained or in a reasonably usable form or forms.” Various components may be required to produce ESI in the form it was originally maintained or a reasonably usable format. For most of the files produced, the components include:
- File formats
- Searchable text
- Fielded data
- Bates numbers, stamps and redactions
- Load files
3.1. File Formats
ESI can be collected, processed and output to a variety of formats for document review. (See Processing Guide for processing output options.) Once the review is complete and the production set is identified ESI can be produced in various production formats depending on the native file types and the requirements of the document production. Because document review sets may have a variety of native file types (i.e. .doc, .xls, .pst, .nsf), it is not unusual for a production to have more than one production format. The production formats for ESI files can be classified as native, near-native, image (near-paper) and paper.
3.1.1. Native File Formats
Producing files in the format they were created and maintained is known as a native production. In a native production, MS Word documents are produced as .doc or .docx files, MS Excel files are produced as .xls or .xlsx files, and Adobe files are produced as .pdf files, etc. Native format is often recommended for files that were not created for printing, such as spreadsheets and small databases. For some file types the native format may be the only way to adequately produce the documents.
For instance, Microsoft Excel spreadsheets do not lend themselves to being converted to image because the worksheets often do not conform to a standard 8 ½ by 11 inch page. Even if the number of rows and columns do conform to a standard size of paper, there are often formulae and other information that is essential to the matter at hand that require the files to be produced in native format. Small databases are another good example of native data that may best be produced in native format.
E-mail is not typically produced in native format. E-mail is typically stored and maintained in an e-mail system that is like a database (MS Outlook, Lotus Notes, Groupwise, etc). E-mails may be exported to native format from the e-mail system in various formats including .psts for Outlook and .nsfs for Lotus Notes. These files are typically converted to individual files during processing for the document review. There are numerous e-mail systems and users may have various methods for saving or archiving e-mail. In these instances, some e-mails may be produced in native format. One example of a native e-mail production may be where a user saved individual e-mails outside of the e-mail system as Outlook .msg files. These individual messages could be reviewed and produced in native format.
There has been much discussion about “native file production” but there is no defined standard or formal rule requiring native file production. The Federal Rules of Civil Procedure do not mandate native file production but do require parties to negotiate the form(s) of production.
Below is a chart containing some of the pros and cons for native file production:
| Pros | Cons |
|---|---|
| Eliminate image conversion costs | Cannot individually number or endorse pages for document control |
| Eliminate image conversion turnaround time and could result in more timely delivery of documents | Cannot redact |
| Certain files such as spreadsheets and small databases are more likely to be in a format conducive for review | Cannot brand pages with confidentiality endorsements |
| Files are searchable | Risk of accidental alteration is greater than with image (near-paper) format |
| Metadata may be hidden and not fully reviewed prior to production | |
| May require native application or provision of client’s proprietary software to open files. |
Recommendations for Native Productions
Some suggestions to consider when producing native files include:
- Hashing – Hash the documents prior to production to avoid issues regarding authenticity. Commonly used hashing algorithms include MD5 and SHA1. Consider attaching the hash value to the documents as a field for a load file.
- Tracking Produced Materials – Reach an agreement with other parties about how native documents will be managed throughout the discovery process (e.g. how will they be referred to in depositions?). One approach is to create a unique identifying number for each electronic document. If the documents will be used by experts for analysis, agree on how the experts will refer to the documents in their reports.
- Deliver fielded data with each volume containing the following information for each file:
- Document ID
- Original File Name and path
- Modified filename and path
- MD5 hash value
- Production Media – There is no clearly defined format for producing native files, but here is one highly secure and verifiable method for producing native files on a CD, DVD, or hard drive:
- Hash the files
- Rename files with a unique document ID (e.g. ABC000001.doc) (caution: renaming a file may change the MD5 hash value)
- Set files to Read Only
It may be beneficial to include an MD5 Hash tool on the production media. The hash tool can be used to verify that the native file was not inadvertently changed.
3.1.1. Near Native Formats
Some files, including most e-mail, cannot be reviewed for production and/or produced without some form of conversion. Most e-mail files must be extracted and converted into individual files for document review and production. As a result, the original format is altered and they are no long in native format. There is no standard format for near-native file productions. Files are typically converted to a structured text format such as .html or xml. These formats do not require special software for viewing. Other common e-mail formats include .msg and .eml.
Large databases and data compilations are commonly produced in near-native format. Databases can comprise massive amounts of completely undifferentiated tables of data. Enterprise business systems may contain hundreds of tables and thousands of fields of data. The systems may require various database platforms and proprietary software. For these reasons, large databases and data compilations are generally not produced in native format. These databases must often be analyzed by the attorney and client to identify the responsive data and determine the appropriate production format.
Exports from these databases are often produced as text delimited files. In some cases text files are produced with a database diagram, data dictionary, metadata and/or software. Data may also be exported to MS Excel or MS Access for production.
Below is a chart listing some of the pros and cons for near-native files.
| Pros | Cons |
|---|---|
| Eliminate image conversion costs | Cannot individually number or endorse pages for document control |
| Eliminate image conversion turnaround time and could result in more timely delivery of documents | May not be able to redact |
| Data files are more likely to be in a format conducive for review | Cannot brand pages with confidentiality endorsements |
| Files are searchable | Risk of accidental alteration is greater than with image (near-paper) format |
3.1.3. Image (Near Paper) Formats
ESI can also be produced in an image, or near paper, format. Rendering an image is the process of converting ESI or scanning paper into a non-editable digital file. During this process a “picture” is taken of the file as it exists or would exist in paper format. Based on the print settings in the document, the printer or the computer, data can be altered or missing from the image. Expertise in the field of e-discovery and image rendering tools are necessary to minimize this risk. See Processing Guide for further information regarding issues related to rendering images. The chart below lists some common issues when rendering ESI to image format or paper format.
| File Type | Potential Risk |
|---|---|
| MS Word | Auto-dates may display the date the files were converted to image; comments may or may not be displayed; track changes may or may not be displayed; links may not be apparent |
| MS Excel | Hidden cells, rows and columns may or may not be displayed; comments may or may not be displayed; formulas may or may not be displayed; links may not be apparent |
| MS Powerpoint | Speaker notes do not print by default; animations will not display properly; links may not be apparent |
| Various | Embedded images in original not translated into image version and may not be visible |
Processing should always be set up to retain a link from the images to the native files. This will facilitate production if native files are later requested or required for production.
Single page or multi-page TIFF and PDF files are various image formats used for production. Group IV TIFF is the most common format.
Below is a chart listing some of the pros and cons related to image (near-paper) productions.
| Pros | Cons |
|---|---|
| Can individually number or endorse pages for document control | Cost of image conversion |
| Can redact | Increased turn around time due to processing and quality control measures |
| Can brand pages with confidentiality endorsements | Certain files such as spreadsheets and databases may not be in a format conducive for review |
| Risk of accidental alteration once produced is reduced | Risk of altering or missing data during the image rendering process |
3.1.4. Paper
A paper production is just what it sounds like: paper is produced as paper or ESI is printed to paper and the paper is produced. As with converting to image, printing documents to paper can result in missed or altered data. When producing ESI in paper, it is recommended to use someone with expertise in the field of e-discovery and image rendering tools to minimize this risk during the printing or image rendering process.
The chart below lists some common issues when rendering ESI to image format or paper format.
| Pros | Cons |
|---|---|
| MS Word | Auto-dates may display the date the files were converted to image; comments may or may not be displayed; track changes may or may not be displayed |
| MS Excel | Hidden cells, rows and columns may or may not be displayed; comments may or may not be displayed; formulas may or may not be displayed |
| MS Powerpoint | Speaker notes do not print by default; animations cannot be printed as seen; links will not work |
| Various | Embedded images in original not translated into image version and may not be visible |
Paper productions from ESI should only be done if agreed upon by the receiving party since it is not the form in which the documents were ordinarily maintained. Paper format may not be considered a reasonably usable form to the recipient.
If ESI is produced in paper format, consider creating some type of cross reference index between the paper documents and the native ESI files. This will facilitate production if native files are later requested or required.
| Pros | Cons |
|---|---|
| Can individually number or endorse pages for document control | Cost of conversion and printing |
| Can redact | Increased turn around time due to processing and quality control measures |
| Can brand pages with confidentiality endorsements | Certain files such as spreadsheets and small databases may not be in a usable format |
| Risk of accidental alteration once produced is reduced | Risk of altering or missing data during print process from images |
| No link back to native file | |
| No database or text for searching |
3.2. Searchable Text
The second component to native, near-native and image (near-paper) formatted productions is searchable text files. Searchable text files contain the readable text and sometimes the metadata for ESI. The data is extracted from the native or near-native files.
Searchable text can also be generated for paper documents scanned to image. This is done by optical character recognition or OCR.
Searchable text is typically produced in multi-page or single-page .txt files.
Special attention should be given to redacted documents when producing searchable text. The searchable text for redacted documents should be withheld. (See Quality Control section below).
Parties may reach agreement to produce searchable text.
3.3. Fielded Data
The third component to native, near-native, and image (near-paper) formatted production is fielded data. Metadata and other information is typically extracted from the native files when ESI is processed. This data can be produced in a text delimited file for loading in most litigation support software. This data may also be produced in the EDRM XML load file if the review software is XML compliant. See EDRM XML page for details on the XML standard.
One of the key issues to determine and negotiate early in a case is whether the files’ metadata are considered an integral part of the case. This will impact how the documents are collected and reviewed. If the documents have been collected or accessed in a manner that altered metadata, the data produced will be compromised regardless of the form of production. Receiving extracted fields of data (e.g. for emails – author, recipients, date sent, subject) and metadata fields (e.g. for e-docs – creation date, author, date last modified, title) provides the basis of a document database that includes the information listed above plus the relationship between emails and attachments, the original path of the document, and the source of the document. Receipt of this data from the producing party will save time and money for the requesting party throughout the discovery process.
The manner in which files were collected and processed will influence whether there is viable metadata to produce. If the original metadata was not preserved the data produced may reflect the dates collected, or reviewed, as the creation or modification dates. This not only will be misleading, but may result in the failure to produce relevant data; raise questions about the entire collection, processing, and review process; and might lead to allegations of spoliation.
A list of standard fields has been identified as file elements and metadata tags in the EDRM XML load file. (See EDRM XML page for further details.) They include:
| File Elements | Metadata Tags – All Documents | Metadata Tags – Messages | Metadata Tags – Files |
|---|---|---|---|
|
|
|
|
Parties may reach agreement to produce some of these fields, all of these fields or additional fields of data.
Special attention should be given to redacted documents when producing fielded data. Fields that include redacted text should be redacted or withheld.
3.4. Bates Numbers, Stamps and Redactions
The fourth component to consider in any production is the potential requirement to endorse and redact documents. Native and near-native file formats cannot be bates numbered, stamped or redacted. These file formats are typically produced with a unique document number assigned to each file. This number does not appear on the actual document. If stamps or redactions are required, the native and near-native files are converted to image (near paper) formats so stamps and redactions can be applied.
Image (near-paper) files can be electronically stamped and redacted saving a great deal of time compared to manual numbering and redaction of paper. Stamps and redactions are permanently burned into the images being produced.
Paper documents can be manually bates numbered, stamped and redacted as they have been in the past.
3.5. Load Files
The fourth component to a native, near-native, or image (near-paper) formatted production is a load file. This enables the receiving party to easily load the production into a litigation support database. The load file provides a link to the native, near-native, and image (near-paper) files.
Load files organize and allow access to data that has been produced. Each receiving party may have different requirements for the type of load file needed to add the data to its litigation support database. A load file provides technical information or programming to allow each component of the production (images, full text, metadata fields, native files) to integrate or work together. Essentially, a load file connects the different electronic components of a document so all the components can be accessed and viewed together.
EDRM has developed a standard XML load file. Several e-discovery software and service providers are now XML compliant. The adoption of the EDRM XML standard will facilitate an easier transfer of information between a wide range of review platforms. See EDRM XML page for details on the XML standard.
Until this standard is adopted by all software providers, different litigation support databases will continue to require different configurations for the data and load files. If all parties communicate load file requirements and have readily useable components productions can easily be made by each party. Such discussions can significantly reduce issues in loading the information. Clear and precise communications regarding the load file format will save time and money for each party receiving production data.
4. Prepare Files
Once the documents have been reviewed and the production set has been identified, the documents must be prepared for production.
Production delivery should be prepared consistent with the protocol that the parties agreed to employ during the Meet and Confer session(s), as well as directives determined during judicial proceedings. Litigation technology professionals should be used to prepare the production set and address each component included in the Identify Production Requirements section above. This can be a difficult task due to all of the components required in the production and the required formats for various review tools. The receiving party may not be familiar with a particular load file format, they may be using a different version of software or a completely different review tool. In these situations the Litigation Technology professionals should communicate directly to avoid confusion, frustration, delays and escalating costs. Below are recommendations for preparing the files for each component.
4.1. File Formats
The production files are typically identified during review and exported from the document review system to eliminate the non-responsive and privilege documents from the production set. If the document review was done in native format and images are required for production the files must also be converted to image at this time.
In many cases, productions may contain more than one file format. For example, the MS Word documents may be converted to image (near-paper) format, the e-mails produced in HTML (near-native) format and the MS Excel spreadsheets produced in native format. In other cases, everything may be produced in native or near-native formats except where redactions are required.
See pros and cons for producing various file formats in the Identify Production Requirements section above.
4.2. Searchable Text files
Searchable text files may be included when producing native, near-native and image (near-paper) formats. For native and near-native productions searchable text files are typically produced as a field of data, a load file or as separate text files with the same file name assigned to the document. For example:
ABC00001.doc is the native Word file and ABC00001.txt is the searchable text. Or ABC00002.htm is the near-native e-mail file and\r\nABC00002.txt is the searchable text.
Searchable text is more frequently produced in image (near-paper) productions since the images are not searchable. CAUTION: Searchable text files frequently contain text that is redacted from an image during the review process. This is due to the fact that searchable text is usually extracted before redactions are added to images. The parties may decide not to produce searchable text for redacted documents. This will typically result in a split production, part A containing non-redacted files and the searchable text and part B containing redacted files and no searchable text. Although the production is split, the numbering should be sequential as if the documents were in the original order. If parties agree to produce searchable text for redacted images, the images are usually OCR’d after the redactions are burned into the image. The searchable text should follow the same naming convention as noted above.
When producing searchable text, a cross-reference or load file should be provided so the text can be loaded into a review tool.
4.3. Fielded Data
Some or all of the data extracted from the electronic files during processing may be produced as a result of agreements made in the Meet and Confer. It is important for the attorneys to agree to a list of fields that will and will not be produced. Data that has been extracted from electronic documents is commonly produced as fielded data. The fielded data may be produced in a text file with the field names in the header row or in the EDRM XML load file (See EDRM XML page for details). In a text file each data element has a field separator and text qualifiers. These are known as delimiters. See sample fielded data file below:
| DocID | Author | Recipient | Subject | | ABC00001 | Doe,John | Smith,Sue | Minutes to Board Meeting | | ABC00002 | Doe,John | Jones,Fred | Agenda for Sales Meeting |
In the pre-e-discovery world, a simple comma or quote sign could be used as delimiters. However, when processing ESI the variety of characters included in the data has increased tremendously.
The recommended delimiters are:
- ASCII Character 020 – Field separator
- ASCII Character 254 – Text qualifier
- ASCII Character 174 – Return value
4.4. Bates Numbers, Stamps and Redactions
4.4.1. Native and Near-Native Files
Files may not be produceable in the native or near-native format if stamps, labels or redactions are required.
Instead of a bates stamp, files produced in native or near-native format are usually assigned a unique document number. In most cases, the file will be renamed with this unique number and the original file name will be provided in a data load file. For example: a file named “Board of Director Minutes.Doc” is produced as “ABC0001.doc”.
Fielded data files serve as a cross reference file and contain the document number and the original file name as shown below.
DocID, FileName\r\nABC0001, Board of Director Minutes.Doc\r\nABC0002, Board of Director Agenda.Doc
Additional fields may also be included in the data load file based on the production requirements.
Files marked confidential are sometimes produced on a separate CD marked confidential. A fielded data file can also identify files marked confidential. Although files can be designated as confidential, they will not print with the “Confidential” stamp. If the stamp must appear on the files when they are printed they must be converted to an image (near-paper) format.
4.4.2. Image (Near-Paper) and Paper Files
Bates numbers, stamps and redactions can be manually added to paper documents or electronically added to image (near-paper) documents. Manual stamping is time consuming and more prone to error. Electronic stamping can be applied quickly to image (near-paper) files and numbering issues are less likely. Electronic stamping will shrink the image slightly and apply the stamp to a small margin on each page, usually the bottom right corner. These stamps are burned into the image for production so they cannot be removed and will always appear when the document is printed.
Redactions can also be added electronically in most document review tools. If native files were used for review, they will need to be converted to image prior to adding redactions. Redactions are typically added by the review team prior to production. Electronic redactions are made with a white background and the word “Redacted” displayed on top or a black background. Redactions are burned into the image at the time of production so they cannot be removed and will always appear when the document is printed.
4.5. Load Files
A load file is used to add the files into a document review database. It links the native, near-native, and image (near-paper) files to the Document ID, text, and fielded data being produced. There are various load file formats depending on the software application. Some of the common load files include .dii (Summation), .lfp (IPRO), and .opt (Concordance/Opticon). There are tools to assist litigation technology professionals in converting load files from one application to another.
EDRM has developed a standard XML load file. Several e-discovery software and service providers are now EDRM XML compliant. The adoption of the EDRM XML standard will facilitate an easier transfer of information between a wide range of review platforms. See EDRM XML page for details on the XML standard.
Overall, the adoption of this standard will have the following effects on overall production efforts:
- Reduce the costs of moving data from one step to the next, one program to the next, and one organization to the next.
- Minimize error and error checking rates.
- Decrease cycle times for production and delivery of data packages.
- Lower the likelihood of discovery disputes with a highly adaptable load file format.
Prior to requesting XML as a load file format, it is necessary to confirm that the producing party is utilizing a service that conforms to the XML standard. This is a subject that must be discussed at any Rule 26(f) Meet and Confer prior to engaging in discovery efforts.
5. Copy Files to Media
Data can be stored and delivered on a wide variety of media. These might include CDs, DVDs, portable (external) hard drives, flash drives or an online web repository. The choice of media can significantly impact the amount of time and expense that will be required to load and process produced data. Media is typically selected based on the size of the production. Additionally, consider whether the media is read-only, read/write and encryption capabilities if encryption is needed. If a large amount of data is being produced, it may be better to receive the data on a hard drive rather than tens of DVDs or hundreds of CDs.
In a web-hosted production, documents are stored on an application service provider (ASP) and the requesting party is given secure and controlled access to review and designate documents.
As a frame of reference, the following list indicates approximate sizes for these media:
| CD | 750 MB |
| DVD | 4 GB – 8 GB |
| USB Drive | varies up to 64 GB |
| Hard Drive | Varies up to 100’s of GB |
You may also consider delivering or requesting an on-line production. On-line productions involve access to the production data by the receiving party via a secure log-in to a web accessible database that is usually hosted by a third party service provider. An on-line production may be coordinated by the producing party or the receiving party.
On-line productions may be beneficial in any of the following scenarios:
- Cases where an on-line tool was used for document review
- Cases with a large number of electronic documents
- Cases where the documents are produced to multiple parties
- Parties lacking in-house resources (staffing, server space, review tool etc.)
Parties contemplating an on-line production should carefully consider the following:
- The file format in which the documents will be produced
- What metadata fields will be produced, if any
- Level of database access granted to the receiving party
- Training and support arrangements for the receiving party
- Desired review workflow for the receiving party
- Resources available to the receiving party
- Ownership of data, particularly the receiving party’s work product
- Payment of loading, hosting, accessing, and other costs
As with productions in any medium, ESI produced on-line can be produced in a variety of file formats. Previously discussed production considerations apply to on-line productions as well as to any other production situation. For example, producing documents in native file format will typically allow receiving parties full access to embedded metadata regardless of whether produced on removable media or on-line. Since most vendors charge differently for different file formats on both the production and import sides, production file format can also have an impact on cost. For example, there may be an additional charge if a native review was done and image conversion is needed for the production. Parties should consider and agree upon the production file formats in an on-line production.
The production of metadata fields has been discussed at length in other sections but there may be additional complications in the on-line setting. For example, if the producing party is actually granting the receiving party access to their review database and simply hiding work product and/or selected metadata fields, the producing party should work closely with the hosting vendor to ensure there is no possibility of an unintentional production of work product, non-responsive documents, or privileged documents or information. Test the site by logging in with the same access rights to be given to the receiving party and verify the access and functionality. As with file formats, parties should consider and agree upon which metadata fields will be produced in an on-line production.
Many vendors are able to control database access rights with a great deal of granularity. Rights may or may not include edits to the database, document printing and/or downloading, reporting capabilities, and more. (See the Review Guide for additional information regarding on-line review tools.) The receiving party should consider carefully what rights it expects to need, and the producing party should carefully consider what rights it is willing to grant. Consideration should also be given to who will have access to the log-in names and passwords of the receiving party. Will only the neutral hosting vendor have access to that information?
The determination of how training and support for the receiving party will be provided and paid for is significant and should be fully defined prior to deciding to produce documents in an on-line production. Again, communication and planning will be necessary. If the receiving party is unfamiliar with the review tool, they may require after hours support in addition to training.
Since different vendor platforms vary significantly in terms of look and feel, supported workflows, and customizability receiving parties in particular should consider carefully how they plan to conduct their review prior to agreeing to an on-line production. With this planning complete, the receiving party can realistically assess the usability of a proposed platform for an on-line production.
The resources available to the receiving party may have an impact on an on-line review. For a party with limited attorney review resources an on-line review tool that provides features such as conceptual analysis may be beneficial. A party with limited financial resources that is required to pay the costs for the on-line review may be at a disadvantage. An on-line production should allow anytime, anywhere access to the database, reducing the need for review teams to travel for on-site document review.
Although the costs associated with a hosted database will be incurred by the party who has implemented the hosted platform, the use of the hosted platform for an on-line production may increase those costs. Some additional costs might include:
- Monthly user access fees for the receiving party’s users
- User set-up fees for the receiving party’s users
- Citrix or other access fees for the receiving party’s users
- Printing or downloading charges
- Hourly fees for production database design and administration
- Project or database set-up fee associated with setting up a production database
Consideration must be given to who will pay for these additional costs, and agreement reached prior to the implementation of an on-line production.
In an on-line production situation, the question of data ownership can become complicated. The production itself presumably belongs to the producing party, while any work product applied to the database by the receiving party presumably belongs to the receiving party. Add to this the fact that the data is actually in the possession of the vendor, which may have its own work product interest at least with respect to the output of its processing. Parties should consider these questions carefully, and reach agreements as to who owns what data prior to conducting an on-line production.
There is a presumption that producing parties pay the costs of production barring cost shifting arrangements. The receiving party may incur some costs associated with online productions since the costs may include hosting fees for review. Parties should reach agreement regarding who will bear which particular costs. This question can become particularly complicated in the situation where a joint defense group is sharing a production database.
6. Status and Progress Reporting/Documentation
It is very important to document the history of both paper-based and electronic-based document productions. Every piece of media should be tracked as it moves through the stages of discovery by each person or company handling it. The preservation and documentation of chain of custody is discussed in the Collection Guide. However at the production stage it is equally important to maintain a production history log. Traditionally, this type of log has been kept by paralegals and that tradition can continue. It is important that productions of ESI are tracked the same way as non-electronic productions and it is best that there be a single point of contact for this information, be it a paralegal, an attorney, or someone in the litigation support department.
Consider including the following information in a production history log:
- Date sent
- Sent to (include full contact information)
- Means by which sent (include shipper’s tracking information)
- Description of media sent (including a photocopy of label)
- Components of production (e.g. images, extracted text, fielded data, load file, native files)
- Bates ranges or Document IDs of production
- Location of copy of media
- Document Request to which production is responsive
- Comments
7. Quality Control/Validation
When producing documents it is important that the production be carefully quality checked by the producing party prior to release. The discovery requests and any subsequent agreements concerning the scope and format of the production should be reviewed for both technical and legal compliance. Someone with technical skills should spot check all components before production. This is true whether the processing is done by the in-house litigation support department of a company or law firm or if it is done by a vendor.
If the data was reviewed in native format and images of the native files are produced, the images should be checked to ensure that they accurately represent the native files. For example, an image of a Microsoft PowerPoint file may not include the speaker notes that an author created to accompany the presentation slides. A native file spreadsheet may contain hidden rows or columns that may or may not be viewable when the file is converted to image format depending on the specifications provided for the conversion. There are risks of producing data that has not been reviewed or, conversely, not producing relevant non-privileged data that has been reviewed but does not appear in the imaged version of the file. Thorough documentation of the process of review and conversion of the native files to image format and checking the results can assist in mitigating these risks.
Redactions are particularly tricky. It is important to understand exactly what is being produced and how redacted information is impacted by the production format. It is recommended that each redacted document be checked to be sure the image was accurately redacted or if that is not practical, a sampling of redacted documents should be checked. Native files cannot be redacted without altering the document. Therefore, native files that require redaction must be converted to image format and the image redacted for production. The redacted image may or may not be OCRd following redaction for production purposes but it is important to be sure that the original native file and the original extracted text file are pulled from the production and are not produced inadvertently. It is also important to be sure the redacted information is not included in fielded data, and if it is, to remove it in an agreed upon manner.
As with all productions, be sure to make and retain an exact copy of the production media.
For an e-discovery paralegal production checklist, go here.
8. Receipt of Production
8.1. Loading Data into Your Internal Database
The technical team member(s) should always evaluate, from a technical perspective the production documents received, as well as those being produced. Immediately upon receipt of production media, conduct a preliminary review of the data and provide a memo to the lead attorney, paralegal or team about what was received and an assessment as to completeness and ability to load the data into the review database. Include information about missing components and steps that will have to be taken to make the data usable (or, if applicable, that the data cannot be made usable and why). Include an estimate of the cost and time necessary to make the data usable (include vendor costs, in-house costs and outside counsel fees if applicable).
If an attorney must communicate with opposing counsel to request a new production set, the technical team member might provide draft language in layman’s terms that can be used to explain the problems and the requested solutions. Communications directly between litigation technology professionals can often provide a faster solution. A technical team member should be available to talk or meet with the opposition’s vendor or technical person to communicate about the requested specifications and the issues with the problem production.
When a production of documents is received it may include any combination of images, extracted text, OCR, native files, extracted metadata fields, fields of data from e-mail files, along with a load file to define document breaks and relationships between emails and attachments. The load file will also facilitate the uploading of the production into a litigation support database application. It is important to review the production with a view to completeness and compliance with the agreed-upon technical requirements. When loading the data it is important to keep in mind considerations to prevent alteration of the data received and to facilitate the efficient review by the legal team. Those considerations might include:
- Capture source and all identifying information in fields in the database (e.g. the document request to which the subject production is responsive; producing party; date of production).
- Lock down extracted data and metadata fields that are produced by other parties so data is not altered by the legal team. Some suggestions include:
- Create a shadow field to include the extracted data and metadata fields that can be edited by the legal team. For example, the date of a document according to the extracted data or metadata is 00/00/0000. When the document is reviewed, it is evident that the document date is actually 01/29/1999. Edit the date in the shadow field, not in the original extracted metadata field.
- Hide the extracted metadata fields so the legal team will only see the shadow metadata fields that are editable.
If there are problems with the load files received, first determine how much time is reasonable to attempt to resolve those problems. Do not invest more time than what has been determined to be reasonable given the case-specific circumstances. Someone will be paying to fix something that possibly should be fixed by the producing party. Do not be tempted to spend a lot of time modifying load files to make them work. On the other hand, if there is a quick fix, it may well be worth the time to fix it in order to have the production up and running for the legal team as quickly as possible. If it is necessary to modify the load file, communicate with the lead attorney about the problems so a specific request for a workable load file can be made to opposing counsel for future productions.
8.2. Volume of Data and Accessibility
In the paper discovery world, it was not difficult to scale up for large volumes of unexpected production documents. At the worst, it was inconvenient and might have resulted in additional expense if space had to be leased to accommodate more boxes than expected. However, in the e-discovery world, the unexpected is often the norm. A very small hard drive may contain many more documents than hundreds of boxes would contain. Although the physical space needed to store and manage large volumes of electronic data and images may not be readily visible, it must be available and managed.
The amount of space the data requires is difficult to estimate based on the number of documents being produced. It may be greater if productions include image (near-paper) and/or native files containing graphics. Inevitably, the volume of documents actually produced is always more than originally anticipated. Always plan on more rather than less. The data may be loaded into an in-house review tool or application service provider (ASP).
Consider the following when selecting the appropriate review tool:
- How much server space is required?
- Does the review tool efficiently support the volume and file formats of records?
- Will there be supplemental productions?
- Will the productions be distributed to other parties in the future and require re-stamping or re-review for privilege designation?
- Is it likely that the discovery requests will broaden?
- Will the number of custodians or sources of documents grow?
- Will third parties be producing large amounts of data in response to subpoenas?
- Who needs access to the production set? Are users in multiple physical locations?
- Can the selected tool support multiple user groups in various locations?
- What levels of security are required for the various user groups?
- What type of analysis/search tools are needed for the review?
See the Review Guide for additional information on selecting review tools.
9. Recommendations
- Involve technical team members early in the discovery process.
- Plan for and expect open communication between the parties about production issues.
- Understand how different types of documents are impacted by processing and production form(s).
- Native format recommendations:
- Native format production may be the only option for files that were not created for printing such as spreadsheets and small databases.
- Hash the documents prior to production to avoid issues regarding authenticity.
- Reach an agreement with other parties about how native documents will be managed throughout the discovery process (e.g. how will they be referred to in depositions?).
- Assess whether or not metadata should be produced.
- If page level endorsements such as redactions, bates numbering and confidentiality stamping are required, the files cannot be produced in native format.
- Near-Native Format
- Near-native format production may be the only option for some files, including most e-mail, which cannot be reviewed for production or produced without some form of conversion.
- Large databases and data compilations are often produced in near-native format.
- If page level endorsements such as redactions, bates numbering and confidentiality stamping are required, the files cannot be produced in native format.
- Image (Near-Paper) Format
- Image (near-paper) format production involves rendering an image by converting ESI or scanning paper into a non-editable digital file.
- Electronically stamp and redact images in image (near-paper) format to save time and money compared to manual numbering and redaction of paper.
- Processing should always be set up to retain a link from the images to the native files.
- Paper Format
- Paper productions from ESI should only be done if negotiated with the other party(s) since it is not the form in which the documents were ordinarily maintained and may not be considered to be in a reasonably usable form.
- Clear and precise communications regarding the load file format will save time and money for each party receiving production data.
- There are two optimal forms of production for ESI: – 1) native file format with fielded metadata or 2) image (near-paper) format with fielded metadata and full text.
- Be prepared to produce documents in the same format in which you request documents.
- Request extracted fields of data (e.g. for emails – author, recipients, date sent, subject) and metadata fields (e.g. for e-docs – creation date, author, date last modified, title) to include in the document database. Additional core information to include in the document database is the relationship between emails and attachments, the original path of the document, and the source of the document.
- Capture production information in fields in the database (e.g. the document request to which the subject production is responsive; producing party; date of production).
- Lock down extracted data and metadata fields that are produced by other parties so data is not altered by the legal team.
- Consider how documents will be used throughout discovery and during presentation.
- The manner in which files were collected and processed will influence whether there is viable metadata to produce. Identify early the metadata that will be produced.
- Special attention should be given to redacted documents. Verify that the redacted information is accurately and fully withheld on the images, in the text and within the fielded data. It may be necessary to OCR the image and replace the extracted text file with the OCR text file.
- The choice of media can significantly impact the amount of time and expense that will be required to load and process produced data. Media is typically selected based on the size of the production. Additionally, consider whether the media is read-only, read/write and encryption capabilities if encryption is needed.
- Carefully quality-check each production prior to release. The scope and format of the production should be reviewed for both technical and legal compliance and someone with technical skills should spot check all components before production.
- Evaluate the production documents received for both technical and legal compliance.
- Make and retain an exact copy of the production media.
- Maintain a production history log.
- Do not invest an unreasonable amount of time in fixing problems with productions and load files.
- Consider using a third party hosted database or application service provider (ASP) if there are any anticipated limitations on the amount of data that can be handled by outside counsel or if access by multiple firms or companies is required.
10. Risks/Analysis
- Some methods of collection and processing may preclude some forms of production.
- The types of ESI available for production and the nature of that ESI will impact the ability to discover the knowledge needed to address the issues in the lawsuit.
- Lack of early communication about production requirements may result in delays during the final stages of production resulting from undisclosed expectations or erroneous assumptions.
- Issues with native file production:
- Cannot individually number or endorse pages for document control
- Cannot redact
- Cannot brand pages with confidentiality endorsements
- Issues with reviewing the production
- Risk of accidental alteration is greater than with image (near-paper) format.
- Metadata may be hidden and not fully reviewed prior to production
- May require native application or client’s proprietary software to open files
- Issues with near-native production:
- Cannot individually number or endorse pages for document control
- Cannot redact
- Cannot brand pages with confidentiality endorsements
- Risk of accidental alteration is greater than with image (near-paper) format.
- Issues with image (near-paper) productions:
- Cost of image conversion
- Increased turn around time due to processing and quality control measures
- Certain files such as spreadsheets and small databases may not be in a usable format
- Risk of altering or missing data during conversion process
- Issues with paper productions:
- Cost of image conversion and printing
- Increased turn around time due to processing and quality control measures
- Certain files such as spreadsheets and small databases may not be in a usable format
- Risk of altering or missing data during print process
- No link back to native file
- No database or text for searching
- Common printing or image rendering issues with common file types:
- MS Word – Auto-dates will display the date the files were converted to image; comments may or may not be displayed; track changes may or may not be displayed
- MS Excel – Hidden cells, rows and columns will not be displayed; comments may or may not be displayed; formulas will not be displayed
- MS PowerPoint – Speaker notes do not print by default
- Various – Embedded images in original not translated into image version and may not be visible
- Redactions are particularly tricky. It is important to understand exactly what is being produced and how redacted information is impacted by the production format. When producing extracted text and fielded data, documents that have been redacted require special and close attention to ensure that the redacted information is removed from all components. This may require reprocessing the redacted images and substituting the reprocessed components for the original components.
- If the documents have been collected or accessed in a manner that altered metadata, the data produced will be compromised regardless of the form of production.
- If the data was reviewed in native format and images of the native files are produced, the images may not accurately represent the native files. There are risks of producing data that have not been reviewed or, conversely, not producing relevant non-privileged data that have been reviewed but does not appear in the imaged version of the file.
- In the e-discovery world, the unexpected is often the norm. Inevitably, the volume of documents actually produced will be more than originally anticipated.